Architecture deep-dive
gocdnext is three Go binaries + a Postgres + an artefact backend. This page walks the moving parts so an operator can debug or extend without reading the whole codebase.
Components
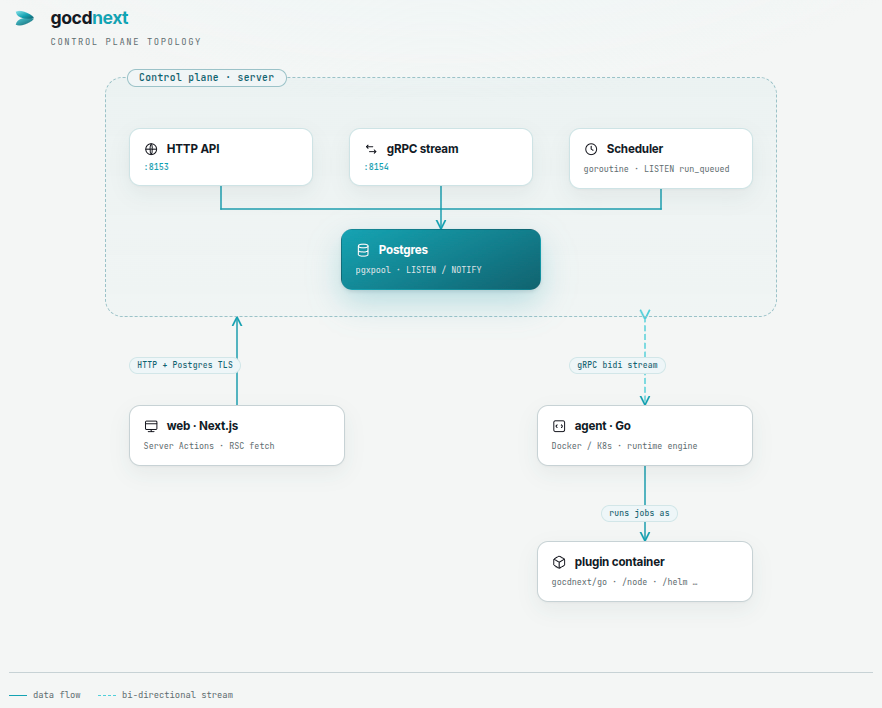
server — the control plane
One Go binary, three roles:
- HTTP on
:8153— REST API, webhooks, SSE log stream. - gRPC on
:8154— agent registration + bidirectional log stream. - In-process scheduler — single goroutine listening on
pg_notify('run_queued', ...), picking up runs as they’re created and dispatching jobs to free agents.
Co-located in one binary because the latency between webhook → run created → job dispatched matters more than the deployment flexibility of separating them. A push-driven build wants to start running within seconds.
agent — the runner
One Go binary per agent host. Maintains a long-lived gRPC stream
to the server (single-writer Send invariant; Send + CloseSend
share the same goroutine). On JobAssignment:
- Resolves materials + signs short-lived URLs for artefact downloads and cache fetches.
- Starts the plugin container (Docker engine OR Kubernetes
engine, depending on the agent’s
GOCDNEXT_AGENT_ENGINE). - Streams stdout/stderr lines back as
LogLinemessages, bulk-batched (100 lines / 200 ms). - Streams
ServiceLifecycleevents for any declared services. - Reports
JobResulton terminal status.
Where material cloning happens depends on the runtime:
- Docker engine — the agent process clones, then mounts the workspace into the task container.
- Kubernetes engine, shared mode — the agent process clones, then mounts the shared PVC.
- Kubernetes engine, isolated mode (default since v0.5.0) — the
agent serialises the
JobAssignment(with signed URLs) into a Secret and re-execs itself inside the pod as theprepinit container, which does the clone + artefact download + cache fetch against the pod’s ephemeral PVC. See Kubernetes runtime.
Agents register at boot via Register RPC, get a session token,
hold the stream open. The server’s SessionStore manages capacity
- tag-based routing; the scheduler dispatches jobs to whichever session matches the job’s tag requirements + has free slots.
web — the dashboard
Next.js 15 + React 19, App Router, RSC default. Server Actions hit the platform’s HTTP API for mutations; RSC fetch hits it for reads. Client components use TanStack Query for live polling + SSE subscription for log tailing.
The web tier is stateless — every request goes to the server’s HTTP API. You can run N replicas behind a load balancer.
Postgres — the source of truth
Everything else is a cache or a transient. Postgres holds:
projects,pipelines,materials— pipeline definitions.runs,stage_runs,job_runs— run state.runs.has_servicesis snapshotted at run-create time so list endpoints can skip the service-detail query when there are none.service_runs— one row per declared service per run; lifecycle state machine for services (starting → ready → stopped, orfailed). Sticky-failed enforced at the SQL upsert.log_lines— log stream (RANGE-partitioned by month).artifacts,caches— backend metadata (the bytes are in the artefact backend).artifactshas a partial unique index enforcing one canonical row per(job_run_id, path)after retire-on-retry.secrets(whenbackend=db) — AES-256-GCM-encrypted values.agents,runner_profiles— agent fleet state.runner_profilescarriesenv+secretsJSONB columns (added by migration00030) holding per-profile plaintext env vars and encrypted secret values — used for things like registry creds and layer- cache bucket auth.users,groups,group_members,audit_events— RBAC, approver groups, and audit log.platform_settings— UI-mutable runtime config (storage backend, retention, layer-cache shorthand defaults).
pg_notify + LISTEN is what wakes the scheduler; the channels
are run_queued (new run created) and run_done (terminal flip).
The scheduler holds one dedicated pgx.Conn for LISTEN; the
rest of the platform shares a pgxpool.Pool.
Artefact backend — the bytes layer
Anything that’s not metadata: artefact files, cache tarballs, cold-archived log gzips. Three backends:
filesystem— local PVC. Default. Single-server only.s3— AWS S3, MinIO, R2, any S3-compatible.gcs— Google Cloud Storage.
The platform’s internal/artifacts package abstracts these
behind the same Store interface. Switching backends is a
config change + a one-shot rsync of existing data — no schema
migration.
Request flows
Webhook → run created
- GitHub POSTs to
/api/v1/webhook/github. - HMAC validated against the SCM source’s secret.
- Push event extracted:
(repo, branch, sha). store.InsertModificationupserts a row inmodifications(idempotent — same(material_id, sha)is a no-op).- If a new modification was created,
store.CreateRunFromModificationinsertsruns+stage_runs+job_runsin one transaction ANDpg_notify('run_queued', <run_id>)within the same tx. - The scheduler’s
LISTENgoroutine wakes up, picks up the run, dispatches jobs (see below).
The whole flow is webhook → run dispatched in under a second on a healthy install.
Job dispatch
- Scheduler reads the active stage for the run (lowest ordinal
with
queued/runningjobs). - Atomically claims a
queuedjob:UPDATE job_runs SET status='running', agent_id=$1 WHERE id=$2 AND status='queued'. If 0 rows affected, another scheduler tick beat us — fine, move on. - Constructs a
JobAssignmentproto with the materials, env, secrets, plugin spec. - Looks up an idle session in
SessionStorematching the job’s tags + capacity. - Pushes the assignment onto the session’s outbound channel.
- Send-pump goroutine dequeues + writes to the gRPC stream.
If no session matches (no agent with required tags or all are
full), the job stays queued; the next scheduler tick re-tries.
Log stream
- Agent’s runner writes a line to its in-process channel.
- The send-pump batches lines (100 / 200 ms) into a single
AgentMessage{Log: ...}proto with multipleLogLineentries. - Server’s gRPC handler unpacks the batch, calls
store.BulkInsertLogLines(multi-VALUES INSERT, ON CONFLICT on the triple key). - After the DB write, the server publishes each line to the
in-process
logstream.Broker— SSE subscribers fan out.
The DB lag behind the SSE fan-out is up to flushEvery (~200ms); acceptable per the docs convention.
Cold-archive flow
When a job hits a terminal status:
- The agent_service’s
handleJobResultcallsmaybeEnqueueArchivewhich folds the global policy + project override. - If archiving is on for this job,
archiver.Submit(jobRunID)pushes onto a queue. - The archiver’s worker pool picks up the queue:
- Reads all log_lines for the job.
- Streams gzipped lines into a buffer.
- Uploads via
artifacts.Store.Put. - Stamps
job_runs.logs_archive_uri. - DELETEs from
log_lines.
- Read path:
getRunDetailcheckslogs_archive_urifirst; falls back tolog_linesfor jobs without an archive.
Failures at any stage leave the row in place; the retention sweeper’s reconcile pass picks up stragglers (re-submit jobs without URI; DELETE log_lines for jobs WITH URI).
Concurrency invariants
- Single-writer on gRPC
Send— the agent’s send-pump is the only goroutine that writes to the stream.Recvruns in parallel (different direction = safe). - Scheduler is single-goroutine within a server replica.
FOR UPDATE SKIP LOCKEDon the dispatch query lets multiple replicas coordinate without conflict. - Job claim is atomic —
UPDATE … WHERE status='queued'with the ID predicate. Lost the race? Move on. - Log batch insert is single-job-per-batch — the bulk insert
query is fine with mixed jobs in one batch but the ON CONFLICT
semantics are simpler when batches are homogeneous; the
agent’s send-pump groups by
(jobRunID)accordingly.
Scaling notes
- Server: stateless. Run N replicas. They coordinate via
Postgres (LISTEN/NOTIFY + atomic UPDATEs). Tested up to 10
replicas. Bottleneck above that is Postgres connection count
- LISTEN fanout.
- Agent: scales horizontally. Each agent has its own
capacity (
GOCDNEXT_AGENT_CAPACITY). Tag-based routing partitions work. - Postgres: vertical scaling matters most. Heavy log
insert load benefits from
wal_level=logical+ tuning the shared buffer + WAL sender count. Partitionedlog_linesis the single biggest scalability win — keeps the heap from becoming the bottleneck. - Web: stateless Next.js. N replicas behind a load balancer.
Where to look in the code
| Component | Path |
|---|---|
| HTTP routes | server/cmd/gocdnext-server/main.go |
| Webhook handlers | server/internal/webhook/<provider>/ |
| Pipeline parser | server/internal/parser/ |
| Scheduler | server/internal/scheduler/ |
| gRPC service | server/internal/grpcsrv/ |
| Store (Postgres ops) | server/internal/store/ |
| Plugin catalog | server/internal/plugins/ |
| Agent runtime | agent/internal/runner/ + agent/internal/engine/ |
| Web pages | web/app/ |
| Web components | web/components/ |
| Server Actions | web/server/actions/ |
The codebase keeps each file under ~400 lines (per CLAUDE.md
house rules), so navigating it is quick. Read the package’s
top-level comment in any file you open — they’re written for
the next reader, not the compiler.